とあるところでマルチホームの構成を組まなきゃならない事になったので、手元のUbuntu(とCentOS)で色々テストしてみました。
結果から言うとiproute2を使えば、マルチホームが組めます。
例えば簡単に考えるとNICを2枚差しして別々のIPアドレスを振って、ISP毎に別のルータを介して接続します。
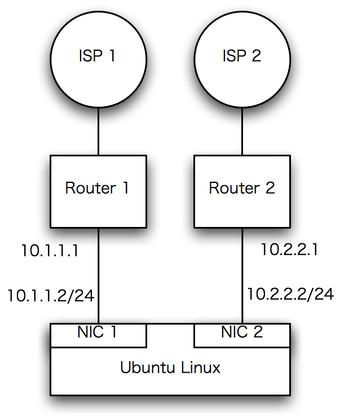
こうすると、Linuxのルーティングテーブルが1つしかない為、Linuxのデフォルトルートが10.1.1.1(ルータ1)に向いていた場合、入ってきたインターフェース(NIC2 = 10.2.2.2)と出て行くインターフェース(NIC1 = 10.1.1.2)が違ってしまい、ISP2からのリクエストをISP1から応答する事になるため、通信が行えない事になります。
また、LinuxからISP1を経由したインターネットへのアクセスは行えますが、ISP2へのアクセスはスタティックルートで指定したIPアドレスを除き、出来ない事になります。
ネットワーク機器の場合、バーチャルルータやVRF等の機能を持っていれば複数のルーティングインスタンスを起動することが出来るため、ルーティングインスタンス毎に別のデフォルトルートを指定する事ができたり、ソースルーティングやポリシーベースルーティングの機能を使って、目的に応じてデフォルトルートを振り向けることが出来るのですが・・・。
Linuxのiproute2が入っている場合、このルーティングテーブルを複数持つことができるため、ISP1とISP2に同時に接続する事が出来るようになります。
先にiptable2のルーティングテーブルを複数持たせる設定を行います。
/etc/iprotue2/rt_table2
#
# reserved values
#
255 local
254 main
253 default
0 unspec
#
# local
#
#1 inr.ruhep
2 ISP2
このファイルの255 local、254 main、254 default, 0 unspecは最初から記載のあるエントリです。そして2個目のルーティングテーブルとして2 ISP2を追記しました。
Ubuntu(debian)の場合、NICの設定は/etc/network/interfaceで行うのですが、1枚目のNICは普通に記述します。
auto eth0
iface eth0 inet static
address 10.1.1.2
netmask 255.255.255.0
network 10.1.1.0
broadcast 10.1.1.255
gateway 10.1.1.1
そして2枚目のNICは
auto eth1
iface eth1 inet static
address 10.2.2.2
netmask 255.255.255.0
post-up ip route add 10.2.2.0/24 dev eth1 src 10.2.2.2 table ISP2
post-up ip route add default via 10.2.2.1 table ISP2
post-up ip rule add from 10.2.2.2 table ISP2
post-down ip rule del from 10.2.2.2 table ISP2
という風に記述します。
CentOSの場合、NICの設定は/etc/sysconfig/network-scriptsで行うので、
/etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
BOOTPROTO=none
ONBOOT=yes
NETMASK=255.255.255.0
IPADDR=10.1.1.2
GATEWAY=10.1.1.1
TYPE=Ethernet
USERCTL=no
IPV6INIT=no
PEERDNS=yes
/etc/sysconfig/network-scripts/ifcfg-eth1
DEVICE=eth1
BOOTPROTO=none
ONBOOT=yes
NETMASK=255.255.255.0
IPADDR=10.2.2.2
TYPE=Ethernet
USERCTL=no
IPV6INIT=no
PEERDNS=yes
/etc/sysconfig/network-scripts/rule-eth1
from 10.2.2.2 table ISP2
/etc/sysconfig/network-scripts/route-eth1
10.2.2.0/24 dev eth1 src 10.2.2.2 table ISP2
10.2.2.0/24 dev eth1 src 10.2.2.2
default via 10.2.2.1 table ISP2
という風に記述します。
ルーティングテーブル(それぞれ)を確認すると、
$ sudo ip route show table main
10.2.2.0/24 dev eth1 proto kernel scope link src 10.2.2.2
10.1.1.0/24 dev eth0 proto kernel scope link src 10.1.1.2
default via 10.1.1.1 dev eth0 metric 100
$ sudo ip route show table ISP2
10.2.2.0/24 dev eth1 scope link src 10.2.2.2
default via 10.2.2.1 dev eth1
という具合に、mainのテーブルと ISP2(と名付けた)テーブルのそれぞれが別のゲートウェイを向いているようになります。
追加作成したテーブル(ISP2)はip ruleコマンドで確認出来ます。
$ ip rule
0: from all lookup local
32765: from 10.2.2.2 lookup ISP2
32766: from all lookup main
32767: from all lookup default
この状態であれば、ISP1からNIC1に入ったクエリはNIC1からISP1経由で応答し、ISP2からNIC2に入ったクエリはNIC2からISP2経由で応答する事ができるため、マルチホームに対応する事が出来るようになります。
但し、F5のBIG-IPやRadwareのLinkproof、PIOLINKのPAS等のWANマルチホーミング装置を使った場合は、インターネットからのincoming方向の負荷分散や、冗長化(片方の回線がダウンした場合に、もう片方の回線にトラフィックを片寄せする機能)を行う為に、インターネット側に応答するDNSパケットを細かく制御してくれますが、Linuxのiproute2のマルチホーミングではそこまでの対応はしてくれません。
Linuxだけで何とかしてみる方法としてiproute2での対応は、負荷分散についてはある程度工夫することで対応出来るかと思いますが、単純なラウンドロビンではなく、回線負荷も考慮した動的な負荷分散は難しいですし、片方の回線がダウンしたときの処理を考えると可用性の向上も難しいでしょう。
それにしても、、、おとなしくWAN回線のinboundトラフィックのマルチホーミング装置があれば、このような方法は取らなくても良いのですが、、、。